

科学知识主要存储在书籍和科学期刊中,通常以 PDF 的形式存储。然而,PDF 格式会导致语义信息丢失,尤其是数学表达式。我们提出了 Nougat(学术文档的神经光学 理解),这是一种 Visual Transformer模型,它执行光学字符识别(OCR)任务,将科学文档处理为标记语言,并证明了我们的模型在新的科学文献数据集。所提出的方法提供了一种有前途的解决方案,通过弥合人类可读文档和机器可读文本之间的差距,增强数字时代科学知识的可访问性。我们发布模型和代码以加速科学文本识别的未来工作。

一、Nougat是什么?
数学公式表格都能识别。Meta AI 推出了一个 OCR 神器Nougat。Nougat 基于 Transformer 模型构建而成,可以轻松的将 PDF 文档转换为 MultiMarkdown,扫描版的 PDF 也能转换,让人头疼的数学公式也不在话下。
Nougat 不但可以识别文本中出现的简单公式,还能较为准确地转换复杂的数学公式。公式中出现的上标、下标等各种数学格式也分的清清楚楚,还能识别表格,不过Nougat 生成的文档中不包含图片。

二、Nougat的地址:
1、论文地址:
https://arxiv.org/abs/2308.13418
2、Github仓库:
https://github.com/facebookresearch/nougat
三、为什么要做Nougat?
在数字化信息高速发展的今天,学术界对于高效、准确的数据转换工具的需求日益增加。作为科研打工仔(bushi),我们平时在阅读论文或者科学文献时见到的文件格式基本上是 PDF(Portable Document Format)。据论文介绍,PDF 也已经成为互联网上第二重要的数据格式,占总访问量的 2.4%。
然而,存储在 PDF 等文件中的信息很难转成其他格式,尤其对数学公式更是显得无能为力,因为转换过程中很大程度上会丢失信息。就像下图所展示的深度学习经典论文《Attention is All you Need》这类带有数学公式的 PDF,转换起来就比较麻烦。

为此,MetaAI 便推出了这款 OCR工具————Nougat。Nougat 基于 Transformer 模型构建而成,可以轻松地将 PDF 文档转换为 MultiMarkdown,扫描版的 PDF 也能转换,上面这些让人头疼的数学公式也不在话下。
甚至,可以往更大的方向吹一吹“Nougat 将科学文档处理成标记语言,在人类可读文档和机器可读文本之间架起了一座桥梁。
四、Nougat的模型概览
在论文中,作者将 Nougat 的主要贡献归为以下三点:
1. “Release of a pre-trained model capable of converting a PDF to a lightweight markup language. ”
团队向社区了开源了相关的预训练模型,可以将 PDF 转换为简单的标记语言。Nougat 发布了两个模型(https://github.com/facebookresearch/nougat/releases):0.1.0-base 中的 decoder 是 10层,允许的最大解码长度为 4096,参数量大概是 350M,模型文件大小是 1.31G。而 0.1.0-small 中的 decoder 是 4层,允许的最大解码长度为 3584,参数量大概是 250M,模型文件大小是 956M。
2. “We introduce a pipeline to create dataset for pairing PDFs to source code”
文中描述了一种用于构建将 PDF 文档与其关联源代码配对的数据集的方法。这种数据集开发方法对于测试和完善牛轧糖模型至关重要,可能对未来的文档分析研究和应用有用,这里我们后面也会一起来瞧一瞧。
3. “Our method is only dependent on the image of a page, allowing access to scanned papers and books”
Nougat 的突出功能之一是它能够仅对页面图像进行操作。这使其成为从各种来源提取内容的灵活工具,即使原始文档没有数字文本格式,它可以处理扫描的纸张和书籍。
如下图所示,Nougat 是一个标准的 Encoder-Decoder 框架下的 Transformer 架构,允许端到端的训练,并以 Donut 架构为基础 (https://github.com/clovaai/donut/,这两个模型一个叫‘甜甜圈’ [Donut],一个叫‘牛轧糖’ [Nougat] ,我只能说研究人员是懂命名的 ) 。该模型不需要任何 OCR 相关输入或模块,文本直接由网络隐式识别。
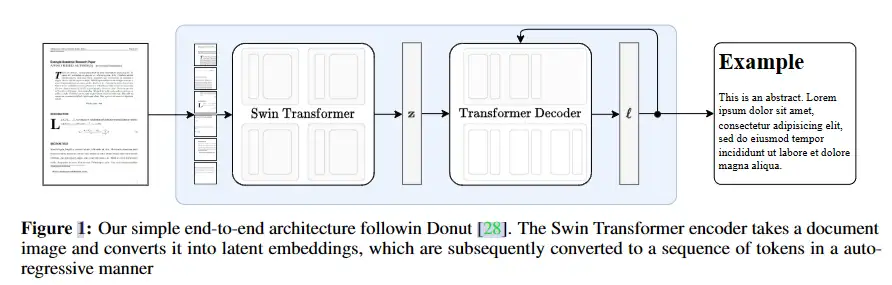
Encoder:Encoder 用的是 20 层的 Swin Transformer(Swin-B {2, 2, 14, 2}),接收文档图像 x ∈ R3×H0 ×W0 ,裁剪边距并调整图像大小以适应大小为 (H, W) 的固定矩形。如果图像小于矩形,则添加额外的填充以确保每个图像具有相同的维度。我们使用 Swin Transformer,这是一种分层视觉转换器 ,它将图像分割为固定大小的非重叠窗口,并应用一系列自注意力层来聚合这些窗口的信息。该模型输出一个嵌入补丁序列 z ∈ Rd×N,其中 d 是潜在维度,N 是补丁的数量。
Decoder:Decoder 用的是文字生成模型 mBART 中decoder,可以看成比较标准的 transformer decoder,使用具有交叉注意的变压器解码器架构将编码后的图像 z 解码为一系列标记。token 以自回归方式生成,使用自注意力和交叉注意力分别关注输入序列和编码器输出的不同部分。最后,输出被投影到词汇表 v 的大小,产生 logits ℓ ∈ Rv。
五、如何使用Nougat?
为了让更多用户能够轻松体验这一技术,我们将Nougat打包成了一键启动包。现在,您无需繁琐地配置Python环境,只需简单点击即可启动程序,从而避免了潜在的环境配置问题。
操作系统:Windows 10/11 64位,显卡:8GB显存以上的NVIDIA显卡
下载压缩包,解压到电脑D盘,最好不要有中文路径;
解压后点击启动.bat文件即可运行(文件可能会被误杀,请添加为信任);
- 浏览器访问:http://127.0.0.1:7860/,即可正常使用。


